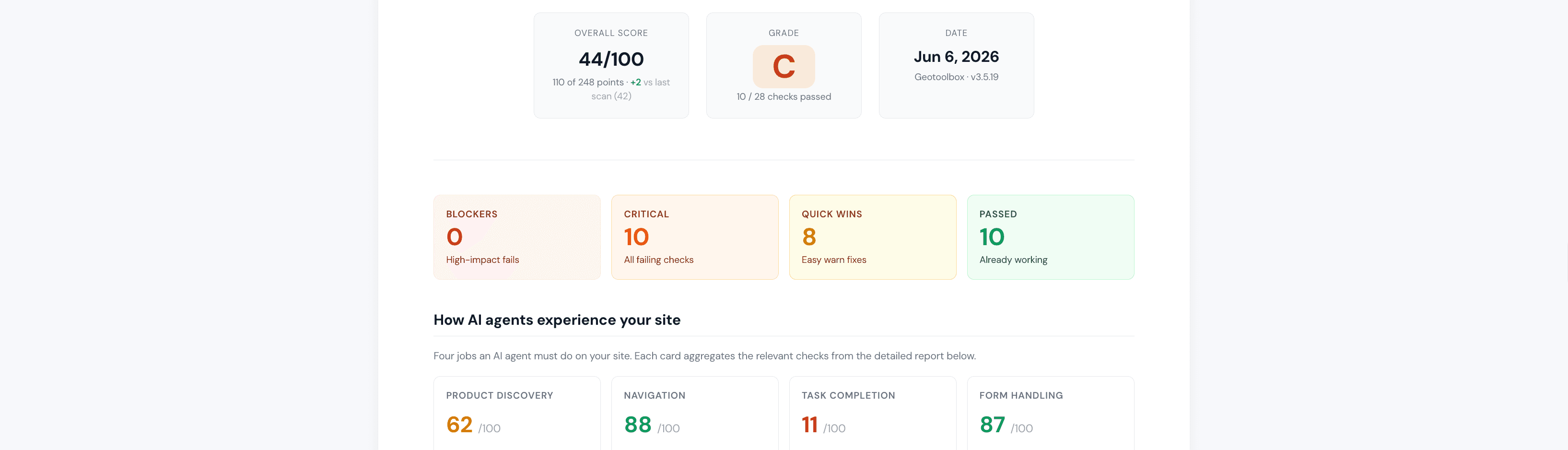
AI Crawler & Agent Readiness
Can AI agents even reach your site?
One forgotten robots.txt line or a JS-only page, and GPTBot, ClaudeBot, and PerplexityBot can't read you — so AI never cites you, and you never see an error. Agent Readiness scans any root URL across 34 AI crawlers, renders the page in a headless browser to show what an agent actually sees, and hands you the exact fixes.
One root URL is all it takes · results in minutes
The blind spot
Block GPTBot in a robots.txt rule someone added months ago, or ship a page whose content only appears after JavaScript runs, and AI engines simply can't read you — no citations, no recommendations, no AI referral traffic. There's no error to catch; you just never show up in the answer.
Agent Readiness scans the whole access path — 34 crawlers, the headless render, JS parity — so you find the blocks before they quietly cost you citations.
From root URL to readiness report in three steps
- 01 · Give
A root URL
Agent Readiness runs infrastructure-level checks, so it starts at your root domain — not a single page.
- 02 · Probe
28 checks across 3 layers
Standards and a 34-crawler access matrix, a headless-Chromium render of what an agent actually sees, and a content-intelligence read of clarity and entities.
- 03 · Fix
A readiness report
The bot matrix, the above-fold capture, the JS-parity diff, and the exact fixes — the PDF adds full hop transcripts and screenshots.
28 checks, 3 layers
Reach, render, and read.
An agent has to get past your robots and firewall, render the page without a real browser, and pull meaning out of it. Each layer checks one of those.
Standards + crawler access
- robots.txt vs 34 AI crawlers
- Sitemap + Link headers
- Content Signals
- Markdown content negotiation
- Agentic content readiness
- Google agent-UX guidance
- schema.org @type validation
What a headless agent sees
- Above-fold screenshot (1280×800)
- JS-rendering parity (JS vs no-JS)
- Console + network health
- JS framework detection
- Form-action detection
Can an agent understand it
- BLUF clarity score
- Entity-density analysis
Act, don't just monitor
Most AI-visibility tools show you the gap and stop. GEO Toolbox shows you the gap — then hands you the fix.
Agent Readiness doesn't just score you — every failed check comes with the source line (the robots.txt rule, the X-Robots-Tag header, the firewall rule) and the one-line fix.
See ClaudeBot blocked? The report shows the exact robots.txt line doing it and what to change — so you unblock it and the next scan flips it to allowed.
Then grade the page itself with Content AnalyzerWhat makes it different
The access path, not just the page.
34 crawlers
Every AI agent user agent
We test your robots.txt and live access against 34 AI crawler user agents — GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, Google-Extended, CCBot, Amazonbot, Bytespider, Applebot, meta-externalagent and more. For each: allowed or blocked, and the source of any block.
Visual capture
What an agent actually sees
A headless Chromium 138 capture of your above-the-fold render at 1280×800. Plenty of sites look fine in your browser and render empty to a bot — this shows the page the way an agent receives it.
JS parity
Content that survives no-JS
Most AI crawlers do not execute JavaScript. We diff the JS and no-JS render and flag any content, navigation, or links that only exist after hydration.
Standards parity
Beyond robots.txt
Sitemap and Link headers, Content Signals, Markdown content negotiation, agentic content readiness, and Google's agent-UX guidance — so an agent can both reach and traverse the site.
Schema validation
Structured data that parses
schema.org @type validation, so the structured data an agent reads is well-formed and type-correct — not just present.
Entity intelligence
Clarity an agent can extract
A content-intelligence pass scores BLUF clarity and entity density: whether an agent can quickly extract who you are and what the page actually says.
Queried live across the engines your customers actually use
- ChatGPT
- Perplexity
- Gemini
- Claude
- Google AI Overviews
- Bing Copilot
- Grok
Every check runs live against your real URL — a headless Chromium render and a live crawl against 34 AI crawler user agents, not a cached guess.
FAQ
Frequently asked
- 01What is agent readiness?Agent readiness measures whether AI agents and crawlers can reach, render, and understand your site. Where a page-level audit asks whether one page is citable, agent readiness asks whether an autonomous agent can fetch, see, and parse the site at all. It runs 28 live checks across three layers: standards and crawler access, a headless-browser visual render, and a content-intelligence read.
- 02Will this help me rank in ChatGPT and Perplexity?It removes the blockers that keep you out of them. If GPTBot or PerplexityBot can't crawl you, or your content only exists after JavaScript runs, those engines can't cite you no matter how good the page is. Agent Readiness clears that access path; Content Analyzer then optimizes the page itself.
- 03How is it different from Content Analyzer?Content Analyzer grades a single page A to F for citability. Agent Readiness works at the site/infrastructure level from a root URL: which of 34 AI crawlers can get in, what a headless agent actually sees, JS-rendering parity, and standards like sitemaps, Link headers, and markdown negotiation. Use Agent Readiness to clear the access path, then Content Analyzer to optimize the page once agents can reach it.
- 04Which AI crawlers does it check?34 AI crawler user agents, including GPTBot and OAI-SearchBot (OpenAI), ClaudeBot, PerplexityBot, Google-Extended, CCBot, Amazonbot, Bytespider, Applebot, and meta-externalagent. For each: allowed or blocked, and the source of any block — robots.txt, a response header, or a firewall rule.
- 05Does it check JavaScript rendering?Yes. We fetch the page with and without JavaScript execution and diff the two. Content, navigation, or links that only appear after hydration are flagged, because most AI crawlers do not run JS. We also detect the JS framework and any form actions.
- 06Can I export the report?Yes. Every probe produces a report you can download as a PDF — the 34-crawler matrix, the above-fold capture, the JS-parity diff, full hop transcripts, and prioritized fixes. Clean enough to hand to a developer, detailed enough to debug.
Scan your site for AI agents.
One root URL is all it takes. Results in minutes.